One of the most commonly encountered challenges in biomedical analysis is that we often have a limited number of samples to study from. Machine learning techniques usually work well with large chunks of data. With inadequate training samples, models are prone to overfitting, potentially leading to failure of generalization and a large drop in performance. However, when we study a rare disease, for example, we may only have a limited number of patient samples to gather data from, resulting in a small dataset for subsequent analysis. Moreover, in many cases of biomedical image analysis, data often suffer from a lack of annotations because labeling multimodal biomedical images requires highly specialized expertise. As a result, biomedical images usually lack adequate annotations in comparison to large-scale natural images. Similarly, for other biomedical data modalities, annotation can be expensive and time consuming, which further aggravates the small sample data dilemma.
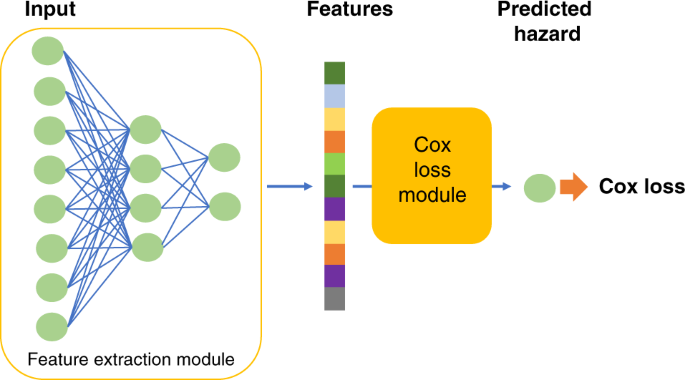
Cancer genomics is one of the research themes at our lab, and using genomic data for cancer survival analysis to help with clinical treatment decisions has been an interesting problem over the past decades. For certain rare diseases, survival analysis has been especially challenging because of the problem of small sample data. In studying a specific rare cancer’s survival outcome, we naturally wonder whether it is possible to make use of the abundant data that is available for more common cancers, and use that information to help with the survival prediction for the target cancer. A visiting student from EPFL, Arnout Devos, who was visiting the lab expressed interest in this problem, and we brainstormed ideas to alleviate the small sample problem. Traditionally this has been widely studied in the realm of transfer learning, where auxiliary data is used to augment learning and algorithms are designed to transfer information from the support domain to the target domain. However, a transfer learning model usually does not explicitly focus on adapting to new tasks efficiently with a very small sample of target training data. Even though the support data and target data may share common features, if the target data is very limited the model may not adapt very well to the specific features of the target task. We came up with the idea of using meta-learning for survival analysis. Meta-learning, also known as “learning to learn”, explicitly learns to adapt to new tasks quickly and efficiently with only a few training samples from the new task environment. The adaptation process, which can be considered as a mini learning session, happens during testing but with a very small exposure to the new task configurations. Such a framework may potentially perform better than the traditional transfer learning in the situation where training samples from the new tasks are very limited, and hence, may be a suitable solution to address the challenge of small sample data in survival analysis.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in